
Most teams test AI systems with the testing mindset they already had. That is the mistake. The tooling can carry over. The mindset cannot.
Traditional testing rests on a contract: a known input produces a known correct output, and the test asserts equality. That contract is the foundation of assertions, regression suites, and the entire concept of a test passing or failing. AI systems violate the contract at its root. The output is not a fixed value. It is a sample from a distribution. Equality assertions are not just brittle here; they are conceptually wrong.
Testing AI is not testing harder. It is testing a different kind of object.
You are testing a distribution, not an output
When you call a deterministic function, there is one correct answer and the test checks for it. When you call a model, there is a distribution of plausible answers, many acceptable, some not, and the same call can land in different places across runs.
This changes the unit of testing. You are no longer asserting “output equals expected.” You are asserting “output falls within an acceptable region of the distribution.” That region is defined by properties, not by a golden string.
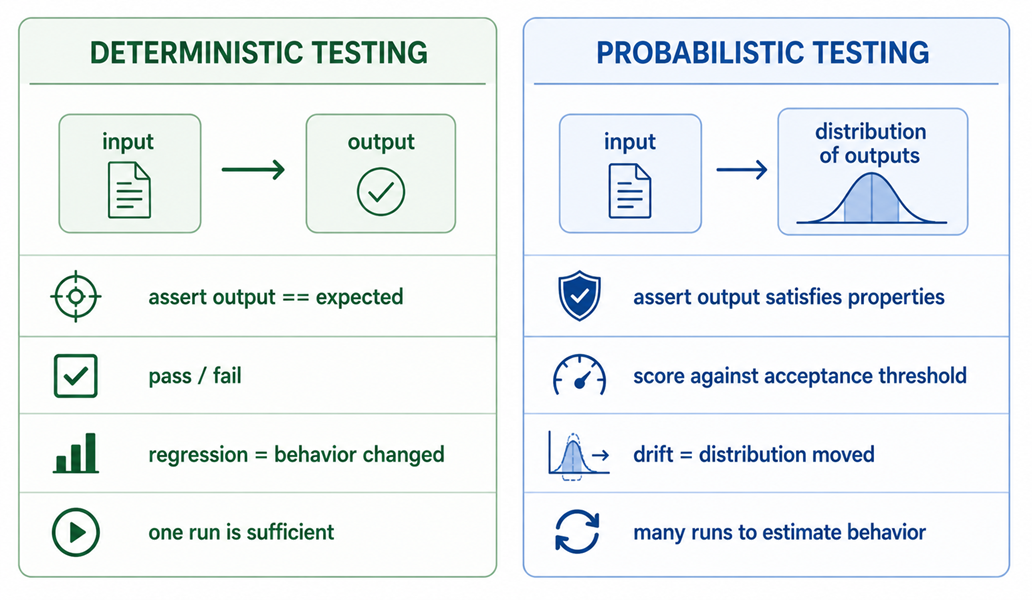
The right mental model is closer to testing a sensor or a statistical process than testing a pure function. You characterize behavior over many samples, you define tolerances, and you watch for the distribution shifting over time. A single run tells you almost nothing.
From assertions to evals
The assertion is the wrong primitive. The right primitive is the eval: a graded judgment of output quality against criteria, producing a score rather than a boolean.
Evals come in layers, and mature AI testing uses all of them:
- Deterministic checks on structure. Is the output valid JSON, does it match the schema, are required fields present, is it within length and format bounds. These are still assertions and they still matter; they catch the failures that are actually binary.
- Property and rule checks on content. Does a retrieval answer cite a source that exists. Does a classifier output one of the allowed labels. Does a summary stay within the source material. These are checkable without a golden answer.
- Reference-based scoring. Where you have ground truth, compare semantically rather than literally. Embedding similarity and metrics like BERTScore measure whether the meaning matches, not whether the string matches.
- Model-graded evals. Use a model as judge to score qualities that resist programmatic checks: relevance, coherence, faithfulness, tone. Powerful and necessary, and the most dangerous, because your test harness is now itself non-deterministic and biased.
The discipline that separates real AI testing from theater is calibrating the model-graded layer. An LLM judge that has not been validated against human labels is a random number generator wearing a lab coat. You calibrate it: sample its judgments, compare to human ground truth, measure agreement, and only trust it on the axes where it agrees with humans. An uncalibrated judge does not reduce uncertainty. It hides it.
From regression to drift
In deterministic software, the thing you fear is regression: a change made behavior worse, and a test that used to pass now fails. The failure is discrete and tied to a commit.
In AI systems, the thing you fear is drift: behavior degraded gradually without any change to your code. The model provider updated the model. The input distribution shifted because real users do not behave like your test set. A retrieval index grew and started returning different neighbors. Nothing in your repository changed, and the system got worse anyway.
Drift is harder than regression because it has no commit to blame and no moment of failure to catch. It requires continuous measurement rather than a gate at merge time. You need a baseline of the system’s behavior on a fixed eval set, run on a schedule, with alerts when the distribution of scores moves beyond tolerance. This is monitoring, not testing in the classic sense, and it never stops.
The implication for QE is significant: the eval suite is not a build-time artifact you run once per PR. It is a production observability system that runs forever, because the system under test can change without you changing it.
The new failure modes you have to test for
AI systems fail in ways deterministic systems do not, and these need dedicated testing rather than hoping the happy-path evals catch them.
- Prompt injection. Content the system processes can contain instructions that hijack it. This is an adversarial input problem and needs adversarial testing, not functional testing.
- Jailbreaks and policy evasion. The system can be coaxed past its guardrails. You test this the way you test security: with a red-team mindset and a growing corpus of attacks.
- Hallucinated confidence. The output is fluent, plausible, and fabricated. Faithfulness evals against source material are the defense, and they are non-negotiable for anything retrieval-based.
- Tool misuse in agents. An agent can call the right tool with wrong arguments, or the wrong tool entirely, in ways that look reasonable in the trace. Testing agents means testing decisions and trajectories, not just final answers.
None of these have an analog in asserting that a function returns 4 when you add 2 and 2.
The trade-off: rigor versus the nature of the thing
There is a real tension worth naming. The deterministic crowd will argue, correctly, that probabilistic acceptance criteria are softer, easier to fudge, and harder to make a release decision on. A test that “scores 0.87 on faithfulness” is genuinely less crisp than a test that passes or fails, and that softness can be abused to ship things that should not ship.
They are right that this is a risk. They are wrong if they conclude the answer is to force AI systems into pass/fail assertions. That just produces brittle tests that break on acceptable variation and pass on unacceptable drift, which is the worst of both worlds. The honest path is to make probabilistic criteria rigorous: fixed eval sets, calibrated judges, defined thresholds with confidence intervals, and trend monitoring. Rigor on a distribution, not false precision on a point.
The crispest possible release gate for an AI feature is not “the test passed.” It is “the eval score is above threshold with this confidence, the drift monitor is stable, and the adversarial suite found nothing new.” That is a different shape of gate, and building it is the actual work.
Key takeaways
- AI testing tests a distribution, not an output; equality assertions are conceptually wrong, not just brittle.
- The primitive shifts from assertion to eval: structural checks, property checks, reference scoring, and calibrated model-graded judgment.
- An uncalibrated LLM judge hides uncertainty rather than reducing it; validate it against human labels.
- The fear shifts from regression to drift, which has no commit to blame and requires continuous monitoring.
- AI introduces failure modes (injection, jailbreaks, hallucination, tool misuse) that need adversarial and trajectory testing, not functional testing.