
There is a recurring failure pattern in how teams build on AI. They pick the best model available, wire their system directly to it, tune everything around its specific behavior, and call it an architecture. It is not an architecture. It is a dependency on a single vendor’s single model, and it is one of the more expensive mistakes you can bake in early, because it gets harder to unwind with every prompt you tune to that model’s quirks.
The frontier moves every few months. The best model today is not the best model in two quarters, and even if it stays competitive, its price, latency, rate limits, and availability will change under you. Coupling your system to one model is the same category of error as coupling your application to one database vendor’s proprietary features. It feels fine until you need to move, and by then moving is a project.
The durable pattern is model routing: treat models as interchangeable backends behind an abstraction, and route each request to the right one based on cost, latency, and measured quality. The model is a runtime decision, not an architectural commitment.
Model worship is a coupling problem
The instinct to standardize on the single best model is understandable and wrong for the same reason most premature standardization is wrong. It optimizes for today’s benchmark at the cost of tomorrow’s flexibility, in a domain where today’s benchmark is obsolete unusually fast.
What actually happens when you couple tightly to one model: your prompts get tuned to its specific behavior, your outputs get parsed assuming its formatting habits, your latency and cost models assume its pricing, and your failure handling assumes its availability. Each of these is a thread stitching your system to that model. The more you optimize, the more threads, and the harder the eventual migration, which is not optional, only deferred.
There is also a reliability problem. A single model is a single point of failure. When the provider has an outage, degrades quality after an update, or rate-limits you during a traffic spike, a tightly coupled system has no recourse. Model worship makes provider availability your availability.
The routing layer
The architectural answer is a layer between your application and the models, the same shape as a database abstraction or a service mesh: an indirection that lets you change what is behind it without changing what is in front of it.
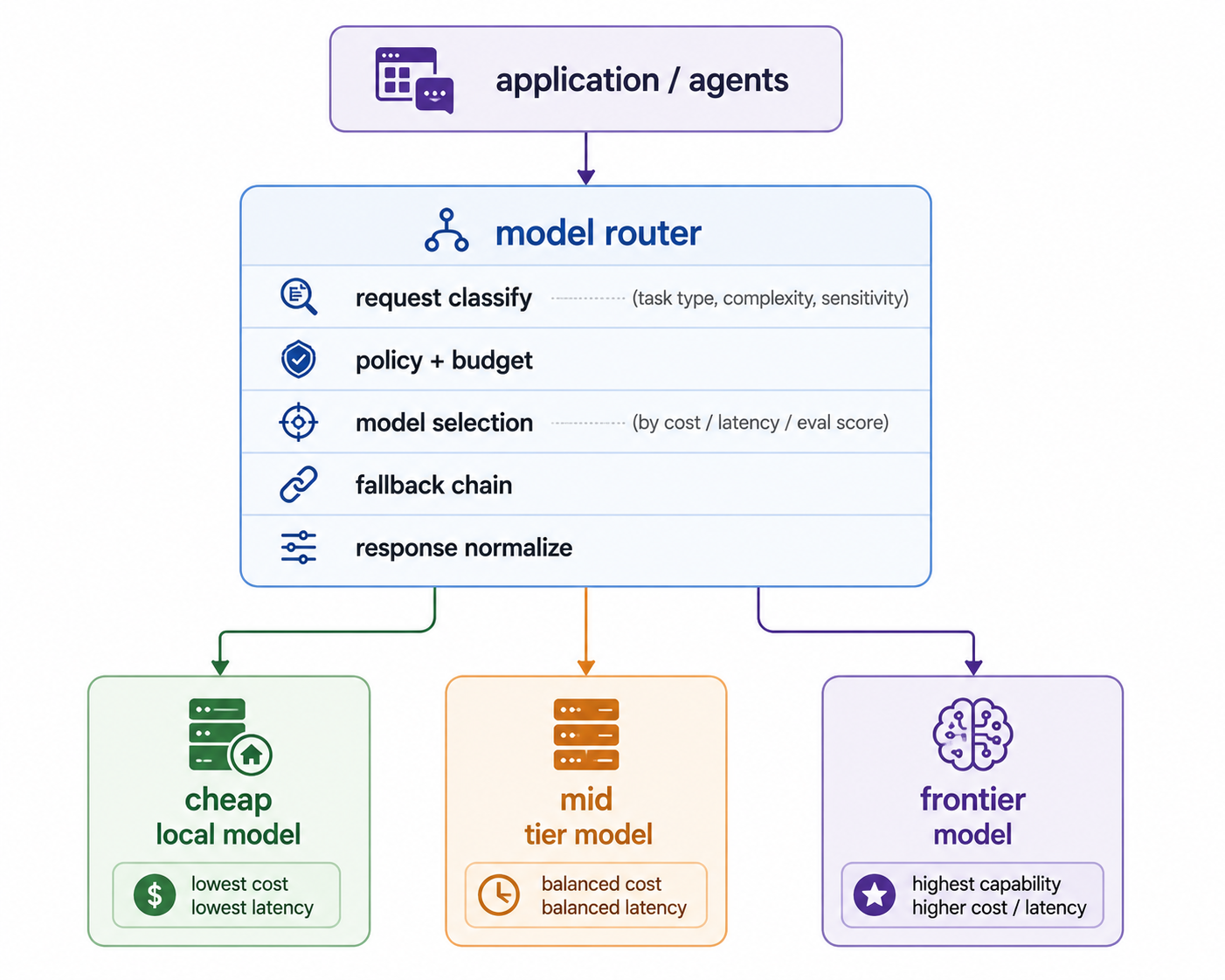
The router classifies each request and sends it to the appropriate backend. A simple, high-volume task goes to a cheap, fast, often local model. A hard reasoning task that justifies the cost goes to a frontier model. A request with sensitive data goes to a model that satisfies your data constraints regardless of raw capability. One decision, made per request, on axes that matter: capability needed, cost tolerated, latency required, data sensitivity.
Behind that sits a fallback chain. If the primary backend is down, slow, or rate-limited, the router degrades to an alternative rather than failing. This converts a single point of failure into a graceful degradation, which is the difference between an outage and a slow afternoon.
And the router normalizes responses, so the rest of the system does not know or care which model answered. That normalization is what preserves your decoupling: the application sees a stable interface, and the model behind it is free to change.
Routing should be driven by evals, not vibes
The naive version of routing uses static rules: this task type goes to this model, hardcoded. That is better than worship but still brittle, because it bakes in an assumption about which model is best for which task, and that assumption decays as models change.
The mature version is eval-driven. You maintain eval suites per task type, you run candidate models against them, and the routing decision is informed by measured quality on the task, not by a guess or a benchmark someone published. When a new model appears, you do not rewrite your system; you run it through the evals and let the data decide whether and where it earns traffic. The router plus the eval suite together form a system that can absorb a changing model landscape automatically, which is exactly the property you want in a field that changes this fast.
This is where quality engineering and AI architecture merge. The eval infrastructure that tells you whether a model is good enough is the same infrastructure that drives the routing decision. The QE function that builds and maintains those evals is directly shaping the runtime behavior of the system. That is a meaningful elevation of the role: from testing the system to governing which model the system uses.
The cost dimension is not a side effect
Routing is also the single largest lever on AI cost, and it is a lever you only have if you built the routing layer. Frontier models can be an order of magnitude more expensive than capable smaller ones. A system that sends every request to the frontier model is overpaying for the majority of requests that a cheaper model would handle identically.
Routing by capability-needed rather than capability-available means you pay frontier prices only for the requests that actually require frontier capability. For most real workloads that is a minority of traffic. The cost difference between “everything goes to the best model” and “each request goes to the cheapest model that is good enough” is large and recurring. Worship is not just architecturally fragile; it is expensive on every request, forever.
The honest trade-offs
Routing is not free, and pretending otherwise would be its own kind of hype.
The router is infrastructure you have to build, operate, and keep correct. It adds latency, a failure mode, and complexity. For a small system with one simple use case, a single model directly wired in is the right call, and building a routing layer would be over-engineering. The pattern earns its keep at scale, across multiple use cases, and over time as the model landscape shifts. Apply it too early and you have built a framework for a problem you do not have.
There is also a real cost to interchangeability: you give up the deep, model-specific optimization that tight coupling allows. A system tuned exhaustively to one model can extract more from it than a system designed to treat all models the same. That is a genuine trade-off, capability ceiling versus flexibility, and for some narrow, stable, high-stakes use cases the tight coupling is the right answer. The mistake is making that the default for everything, because the default workload is neither narrow nor stable.
The general principle holds: in a domain where the underlying components change every few months, the durable architecture is the one that treats those components as replaceable. Model worship bets the system on a snapshot. Model routing bets on the inevitability of change, which is the safer bet in the only field where the SOTA has a shelf life measured in weeks.
Key takeaways
- Coupling a system to one frontier model is a vendor-lock and single-point-of-failure mistake; the frontier moves too fast for that bet.
- A routing layer treats models as interchangeable, tiered backends, selected per request by capability, cost, latency, and data sensitivity.
- Routing should be eval-driven, not rule-baked; the eval suite lets the system absorb a changing model landscape automatically.
- Routing is the largest lever on AI cost: pay frontier prices only for requests that need frontier capability.
- The pattern earns its keep at scale and over time; for a single simple use case it is over-engineering, and tight coupling can extract more from one model.