
Every AI adoption conversation eventually lands on cost, and almost every one gets it wrong. The room talks about the token bill. The token bill is the cheapest cost you will pay.
The expensive costs are structural, and they do not show up on a billing dashboard. They show up six months later as slower reviews, thinner system knowledge, and a pipeline that no longer behaves deterministically.
Let me lay out where the cost actually lands.
The visible cost is a distraction
Inference cost is real, and it is optimizable: cache aggressively, route cheap requests to cheap models, batch, quantize, set token ceilings. This is a solved-enough problem with known levers. Finance can see it, so it gets managed.
The trouble with making the token bill the headline number is that it frames AI adoption as a procurement decision. It is not. It is an architectural decision that changes where work happens in your SDLC, and that shift carries costs that are larger and far harder to see.
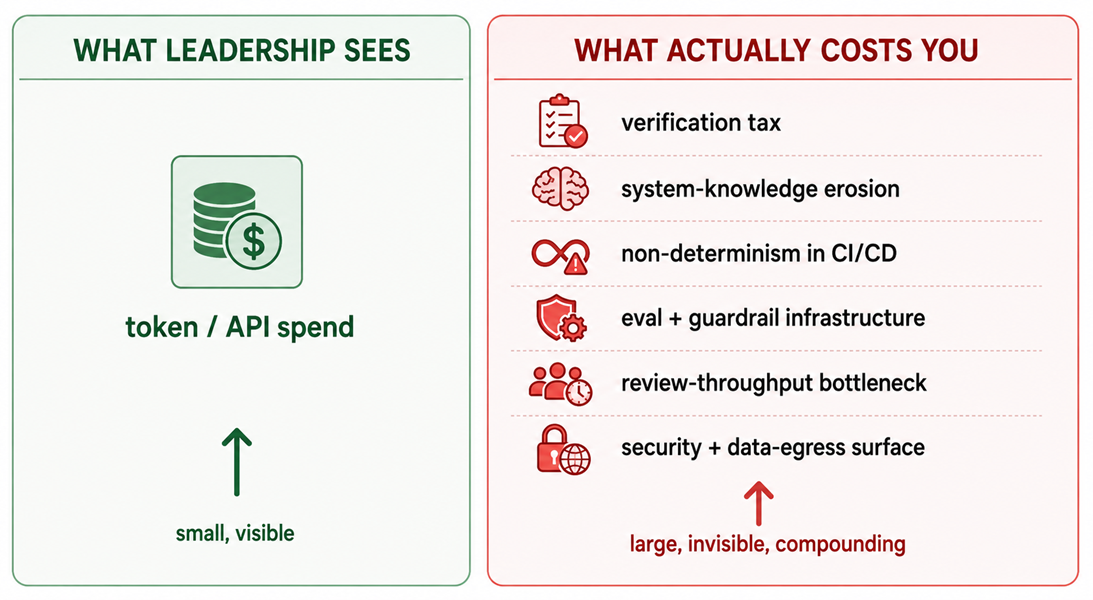
Cost 1: the verification tax
AI shifts work from production to verification. It generates code, tests, configs, and docs faster than any human. It does not verify them faster. A reviewer still has to read every line, and now there is more of it, produced by something with no stake in whether it is correct.
This is the central economic fact of AI-assisted engineering: generation got cheap, verification did not.
Verification does not parallelize the way generation does. You can fan out ten agents to write ten modules. You cannot fan out one senior engineer to meaningfully review ten modules at once. Review is bounded by human attention, and human attention is the scarce resource you just made scarcer by flooding it with machine-generated output.
The result is a throughput bottleneck that moves from “writing code” to “trusting code.” Teams that measured velocity by code produced will report gains. Teams that measure velocity by code safely shipped often will not, because the queue just moved downstream to review and it is now longer.
The mistake is treating the reviewer like a rubber stamp because the code “looks done.” Code that looks done and code that is correct have never been further apart than they are with a fluent model that is confidently wrong.
Cost 2: erosion of system knowledge
When engineers stop writing the first draft, they stop building the mental model that writing the first draft used to produce.
Reading code and writing code build different depths of understanding. Writing forces you to confront every decision: this data structure, this boundary, this failure path. Reviewing lets you skim past decisions that look plausible. Over time a team that mostly reviews AI output accumulates a shallower model of its own system.
This cost is invisible until an incident. During normal operation, nobody notices that the team’s understanding has thinned. During a 2 a.m. production failure, you notice immediately, because debugging requires the exact system knowledge that got outsourced. You cannot prompt your way out of an incident in a system nobody on the team deeply understands.
There is a second-order version of this for new engineers. Juniors used to build understanding by struggling through implementation. If they skip that struggle and go straight to reviewing generated code, the pipeline that produces senior engineers degrades. You are trading short-term throughput for a long-term shortage of the exact people who can review AI output well. That is a slow, expensive feedback loop, and most orgs have not priced it in at all.
Cost 3: non-determinism in a deterministic pipeline
Your CI/CD pipeline was built on an assumption: the same input produces the same output. Compile the same commit, get the same binary. Run the same test, get the same result. The entire concept of a regression depends on it.
LLMs break that assumption. The same prompt can produce different output across runs. If you put a model anywhere in your build, test generation, or release path, you have injected non-determinism into a system whose correctness model assumes determinism.
This shows up as a specific, maddening class of problem. Tests that pass and fail without code changes. Generated configs that drift. Pipelines that are green on Tuesday and red on Wednesday with an identical commit. Teams burn enormous time chasing these as flakes when the flake is structural: a probabilistic component sitting inside a deterministic contract.
The architectural fix is to quarantine non-determinism behind a deterministic boundary. Pin model versions. Set temperature to zero where you need repeatability. Cache and freeze model outputs that feed downstream deterministic steps. Treat the model as an external dependency with a version, not as a pure function. Most teams discover this boundary only after non-determinism has already leaked everywhere, and clawing it back is expensive.
Cost 4: the infrastructure you didn’t budget for
Running AI in production responsibly requires a layer that did not exist in your last architecture review: evaluation harnesses, guardrails, prompt and output logging, regression suites for prompts, data-egress controls, and a way to detect quality drift over time.
This is not optional tooling. Without it you are shipping a non-deterministic component with no observability, which is the single worst kind of thing to operate. But it is real engineering effort, often comparable to building the feature itself, and it rarely appears in the original adoption estimate. The pitch was “the model writes the code.” The reality is “the model writes the code, and now we maintain an eval platform to know whether it is still any good.”
Cost 5: the security and data surface
Every AI integration is a new data-egress path and a new injection surface. Prompts can carry sensitive data out. Tool-using agents can be steered by injected instructions in the content they process. Retrieval systems can leak across tenants if access control is bolted on after the fact.
These are not edge cases; they are the default failure modes, and they are expensive precisely because they are silent. A data leak through a prompt does not throw an exception. It just happens, and you find out later, or never.
How to actually account for it
The fix is not to avoid AI. The leverage is real and the costs are manageable if you see them. The fix is to put the invisible costs on the same ledger as the token bill.
- Budget review capacity as explicitly as you budget inference. If generation goes up 3x, reviewer load goes up too. Plan for it or the queue silently lengthens.
- Protect system knowledge deliberately. Keep humans writing the hard, core, novel parts. Let AI handle the boilerplate where understanding is cheap to lose.
- Treat the model as a versioned external dependency and quarantine its non-determinism behind a deterministic boundary before it leaks.
- Fund the eval and guardrail layer as part of the feature, not as a follow-up nobody schedules.
- Map every AI integration’s data-egress and injection surface during design review, not after an incident.
The organizations that win with AI are not the ones with the lowest token bill. They are the ones that correctly priced the costs that never appear on the bill.
Key takeaways
- Token cost is the smallest and most visible cost of AI adoption; the expensive costs are structural and invisible.
- Generation got cheap, verification did not. Review is the new bottleneck and it does not parallelize.
- Outsourcing the first draft erodes system knowledge, which you only miss during an incident.
- LLMs inject non-determinism into pipelines built on determinism; quarantine it behind a versioned, deterministic boundary.
- Budget eval infrastructure, review capacity, and security surface explicitly, on the same ledger as inference.